- HeyCloud
- Posts
- Cheaper & faster RAG with a SQL layer
Cheaper & faster RAG with a SQL layer
How to build a cheaper and faster Retrieval Augmented Generation system
Abdelhadi Azzouni
January 24, 2024
Efficient RAG system
Context
Data lakes in enterprises typically contain structured, unstructured and semistructured data. Unstructured/semistructured data being roughly 80–90% of the volume src.
Semistructured data is data that is only partially indexed, usually, only a few fields of each document are indexed. This type of data includes: Production logs, audit logs, financial transactions, user related text documents etc but also other multimodal formats such as audio recordings, videos, and more.
Structured data is typically stored in a tabular format in SQL databases, organized into tables with predefined schemas and relationships between entities.
On the other hand, unstructured/semistructured data found in data lakes lacks a predefined structure and does not fit neatly into traditional databases.
The problem
A major challenge for enterprises is how extract business value for unstructured data?
Examples
A banker asks: tell me about the unusual career decisions of my clients under age 25. (Context: the banker has many documents and records per client, for 100s of clients).
A CEO asks: what is the main reason my clients churned in the last 2 weeks? (Context: the CEO has records of the clients churning and notes sent by each client before they churn).
A dev/DevOps engineer asks: what is the main reason for kafka issues last night in eu-west-1 region? (Context: the engineer has kafka logs stored in a document database like elasticsearch)
A lawyer asks: tell me about the last case this company was involved in and ended up losing. (Context: the lawyer has a databse of companies with documents of pas cases).
RAG or “Retrieval-Augmented Generation” is methodology used in large language models (LLMs) like GPT4, Llama etc to generate answers based on external data sources. It is a way of augmenting the LLM with information from external sources, so the LLM acts mainly as a reasoning engine over the data.
The typical RAG uses vector embeddings to store the unstructured data and vector search for identifying the parts of data most relevant to the user query.
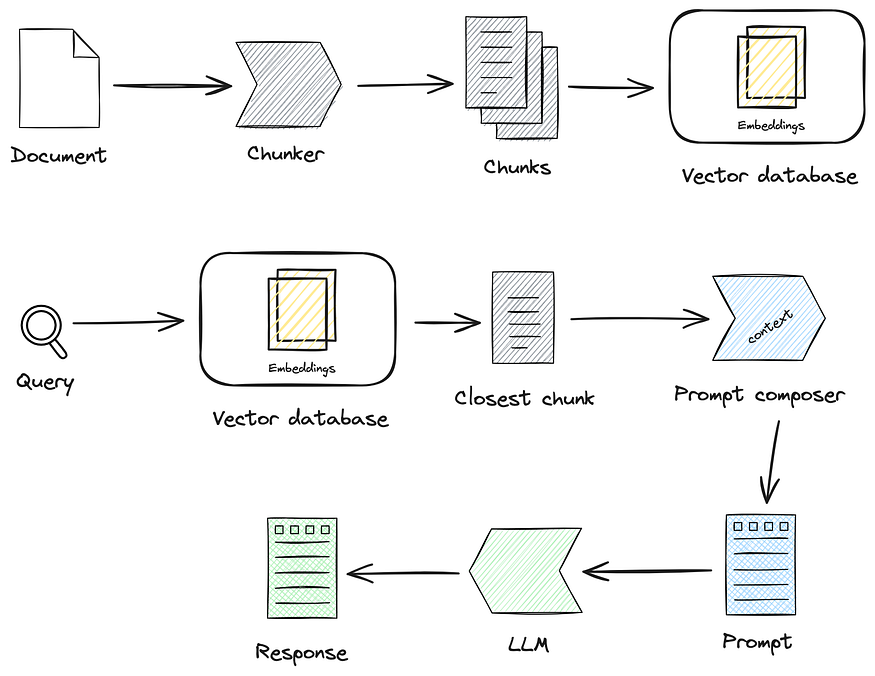
A typical RAG system
The main problem with this approach is threefold:
Expensive: on average, vector databases are much more expensive than traditional SQL databases.
Slow: vector queries are much slower than simple SQL queries.
Quality is not guaranteed with vector search, as it is distance/similarity based search, hence prone to false positives.
Solution: The Two-Tiered Retrieval Approach
The idea is to take advantage of the Semi in Semistructured data. Instead of purely relying on a vector database and treat all data chunks as purely semantic entities, we either index part of the data or use the existing index if any.
The workflow is:
After chunking the data, you link chunks to a SQL index.
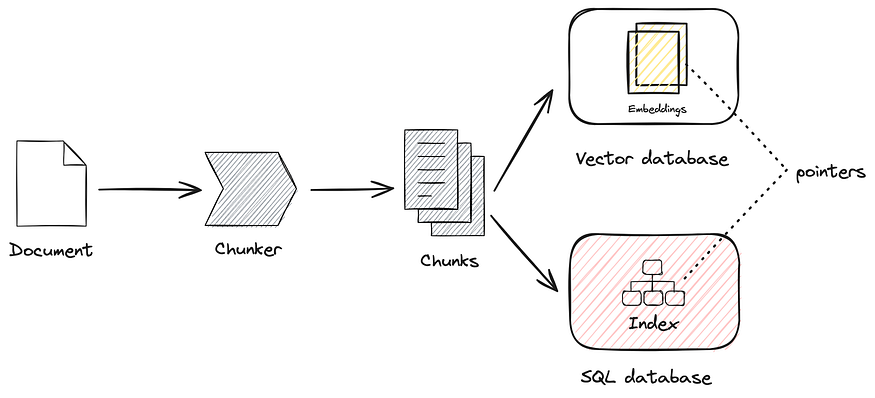
RAG+SQL embedding phase
Examples
Bank clients’ unstructured documents can be chunked and linked back to the existing client database. One way to do this is: inside the chunker, add logic to add metadata pointing to the original client record.
Same for churn data, and lawyer’s clients’ documents.
For logs, it can be slightly different as log documents are usually not that long to be chunked. With logs, the opposite is needed: grouping. More on this in a future blog post that details how we are doing it in HeyCloud.
2. At query time, you start by querying the SQL database first to narrow down the number of vectorised chunks, then you query only those chunks semantically.
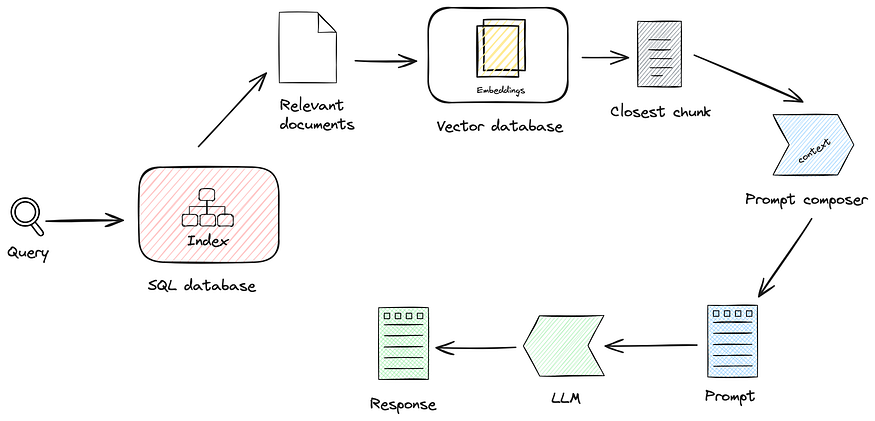
RAG+SQL query phase
Examples
“tell me about the unusual career decisions of my clients under age 25.”
At query time, you query the bank client SQL database for the list of clients under 25. Then, since chunks are linked to the SQL client database, you can select only the corresponding chunks. Finally, you apply a vector search on these chunks.
Same for flow for the other use cases.
Benefits
Efficiency: By first narrowing down the search space with SQL, the vector search has fewer documents to process, which can significantly speed up the vector search process.
Relevance: Because we are using deterministic filters at the SQL stage, this approach ensures that the documents are relevant. Skipping this filter could result in a high rate of false positives, where irrelevant documents are semantically similar to our query.
Complex Queries: It handles complex queries well, wherein SQL can manage the structured fields, and vector search can handle the nuanced, semantic parts.
Conclusion
In summary, combining SQL-based search with vector search in a RAG setup can provide a more refined, efficient, and contextually relevant information retrieval process, enhancing the overall performance and accuracy of LLMs in tasks like question answering and information extraction